



Kiban
title:
tags: ElasticSearch
categories:
- [学习笔记]
- [微服务]
abbrlink: 9d6997a
top_img: https://bu.dusays.com/2024/02/01/65bb3c56d82e7.png
cover: https://bu.dusays.com/2024/02/01/65bb3c56d82e7.png
description: ElasticSreach基本操作
date: 2024-01-24 10:57:09
注意本教程基于Es7.x版本Api编写
启动Es&Kibana
docker start es
docker logs -f es当日志中输出一推的successfully时,基本就启动成功了
docker start kibana
docker logs -f kibana出现5601的链接地址时表明启动成功
数据格式
ES在使用时,会涉及到五个核心概念:索引(Index)、映射(Mapping)、域 (Field)、文档(Document)、倒排索引。以一张MySQL中数据表为例。
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。我们可以把 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。 ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。
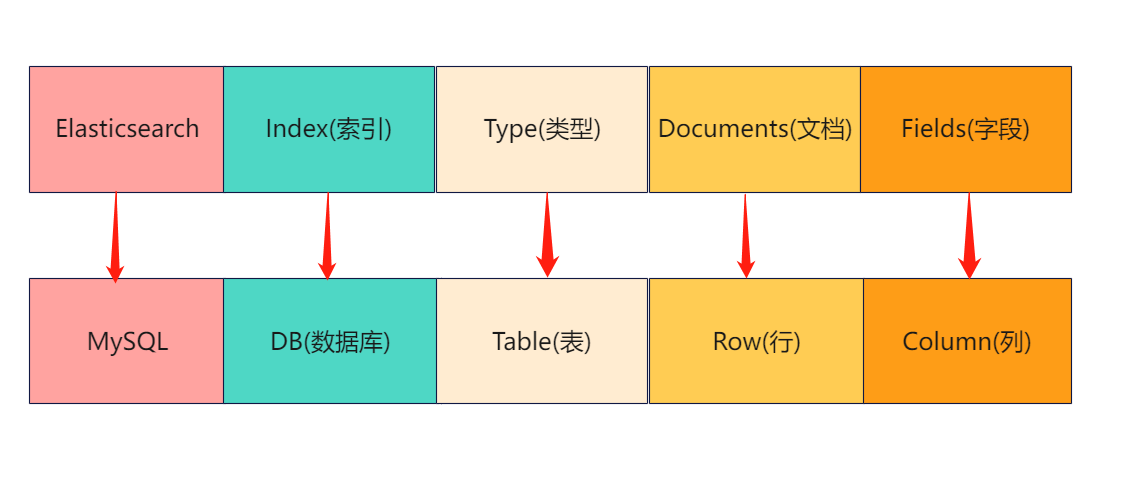 这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
索引操作
索引相当于关系型数据库中的一张表,一个index包含若干document,通过Index代表一类类似的或者相同的document。
打开
kibana的Dev Tools菜单
创建索引-PUT
对比关系型数据库,创建索引就等同于创建数据库
PUT 索引名
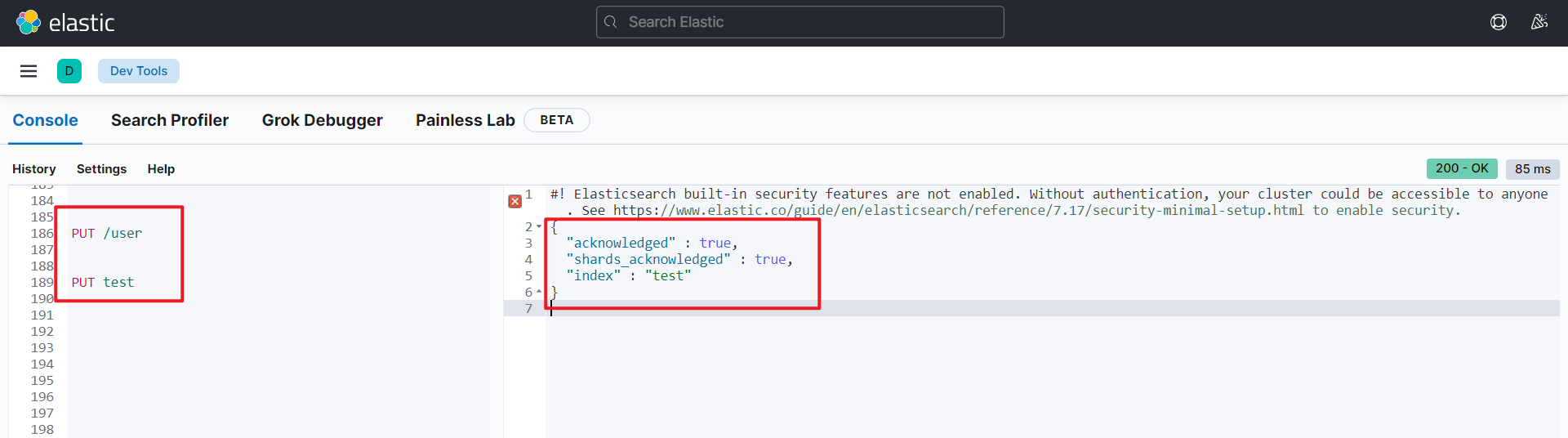
发送请求后,服务器返回了这样的响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test"
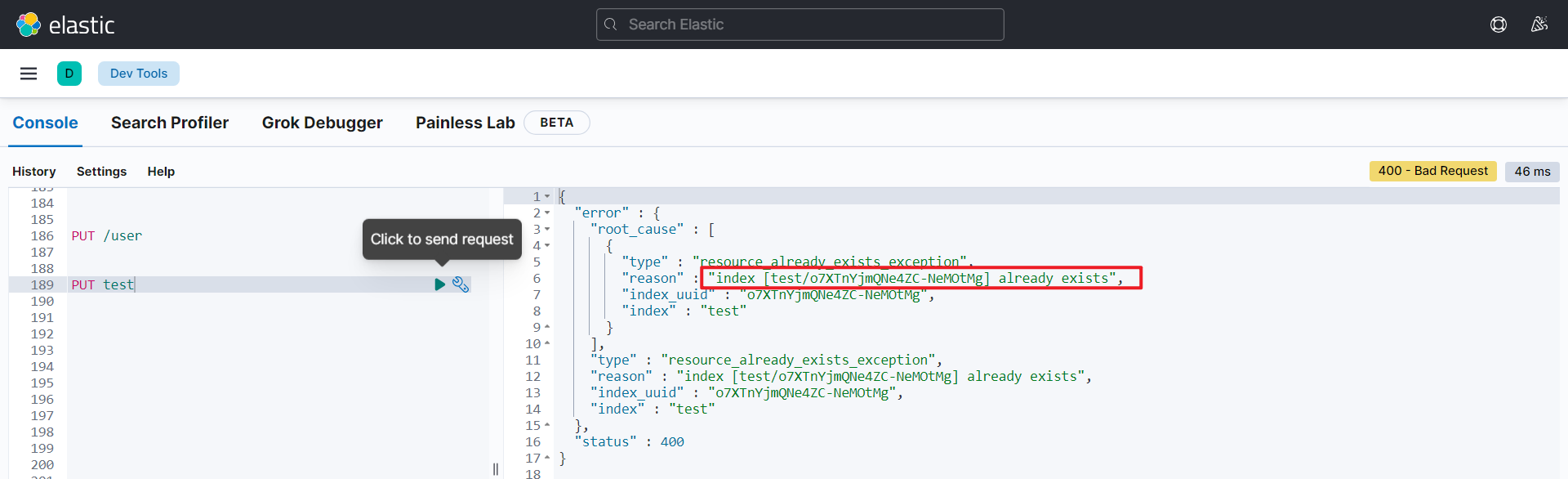
}如果重复添加索引呢?重复添加则会返回索引已经存在的错误信息
查看全部索引-GET
GET _cat/indices?v
GET _all
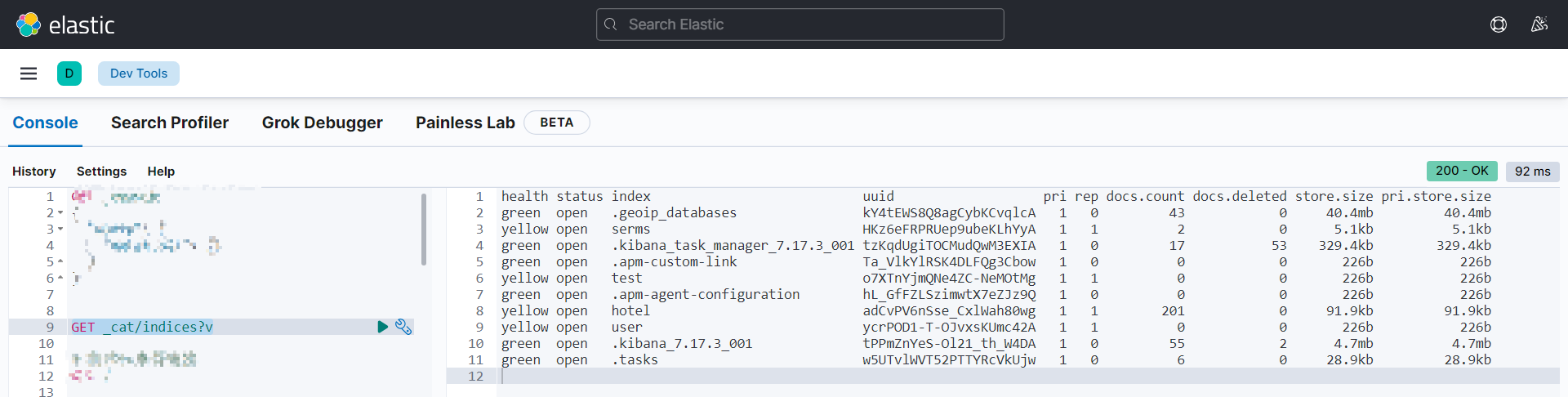
_cat:表示查看的意思;
indices: 表示索引
health:当前服务器健康状态:green(集群完整)、yellow(单点正常、集群不完整)、red(单点不正常)
status:索引打开、关闭状态
index:索引名
uuid:索引统一编号
pri:主分片数量
rep:副本数量
docs.count:可用文档数量
docs.deleted:文档删除状态(逻辑删除)
store.size:主分片和副分片整体占空间大小
pri.store.size:主分片占空间大小
查看单个索引-GET
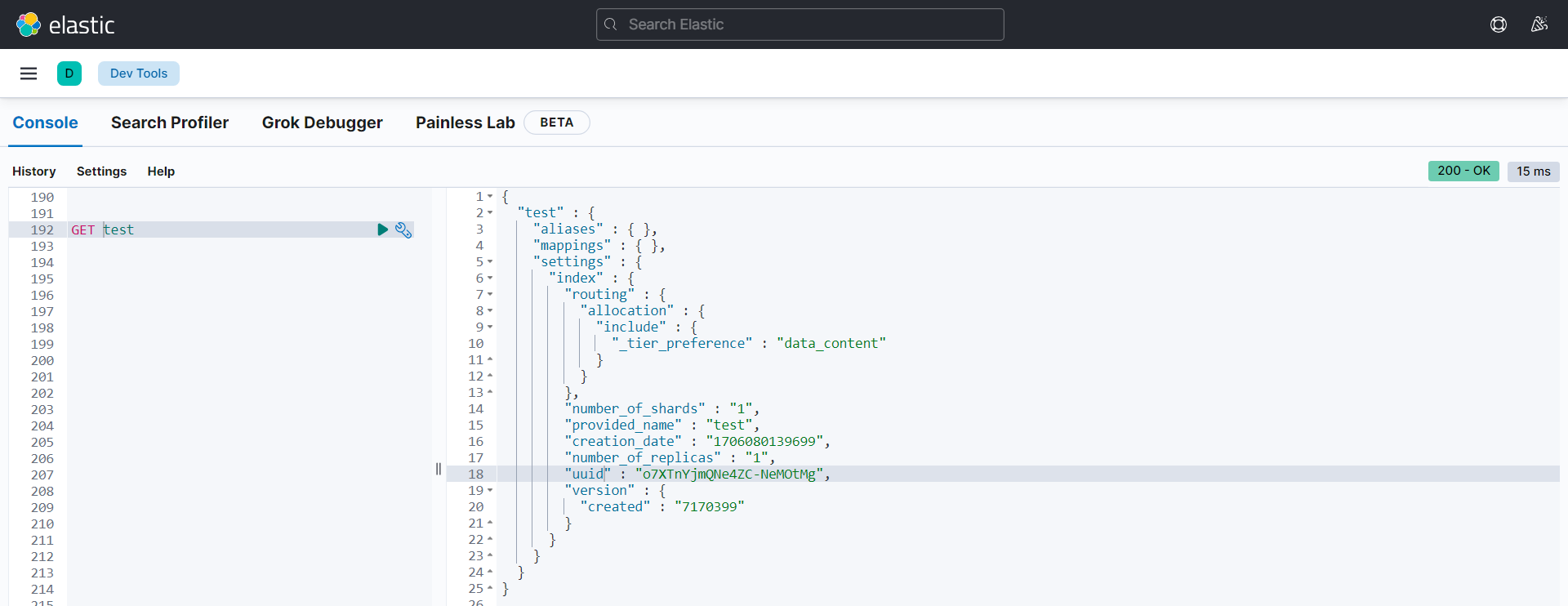
{
"user"【索引名】: {
"aliases"【别名】: {},
"mappings"【映射】: {},
"settings"【设置】: {
"index"【设置 - 索引】: {
"routing"【设置 - 索引路由】: {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"provided_name"【设置 - 索引 - 名称】: "user",
"creation_date"【设置 - 索引 - 创建时间】: "1659678930693",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】: "P0pIpPyTSa-zS7kJCeE7Ng",
"version"【设置 - 索引版本号】: {
"created": "8030399"
}
}
}
}
}查询多个索引
# 查询多个索引信息 GET 索引名称,索引名称
PUT person1
GET person,person1删除索引-DELETE

数据类型
字符串
text:会进行分词,如华为手机,会分成:华为,手机。 被分出来的每一个词,称为term(词条)
keyword:不会进行分词,如华为手机,只有一个词条,即华为手机。
数值
long:带符号64位整数
integer:带符号32位整数
short:带符号16位整数
byte:带符号8位整数
double:双精度64位浮点数
float:单精度32位浮点数
half_float:半精度16位浮点数
布尔:
boolean
二进制:
binary
日期:
date
范围类型:
integer_range
float_range
long_range
double_range
date_range
数组
对象
文档操作
创建文档-POST
先创建好一个索引,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为JSON格式
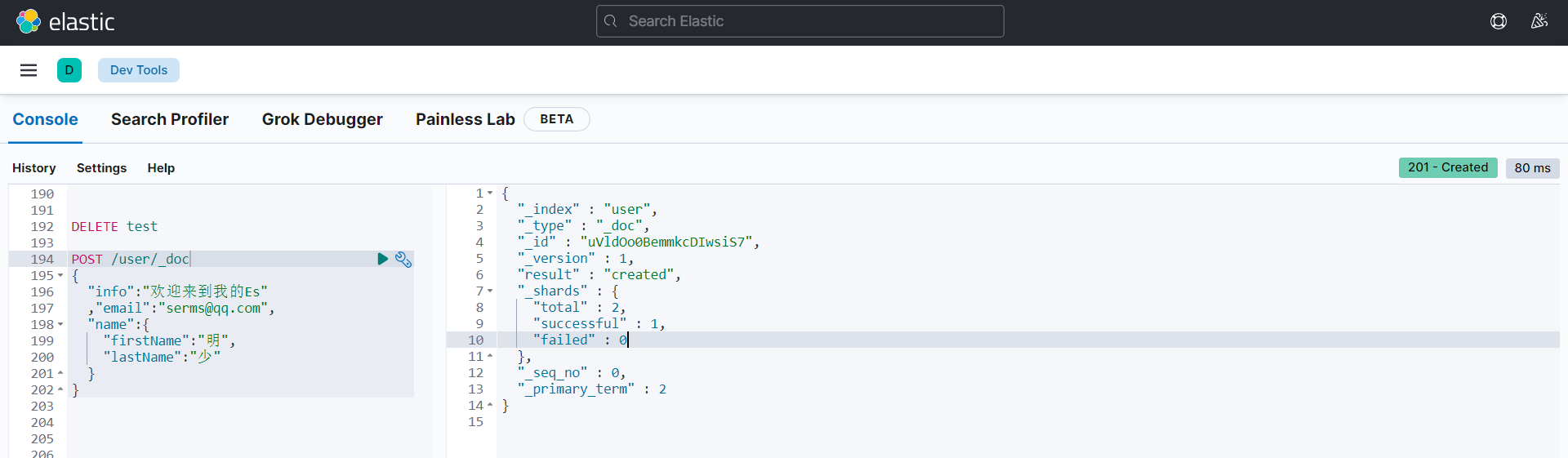
{
"_index"【索引】: "user",
"_id"【唯一标识,支持自定义】: "C1yqbIIBJVfoW_YKu2D5",
"_version"【版本】: 1,
"result"【结果】: "created",#这里的 create 表示创建成功
"_shards"【分片】: {
"total"【分片 - 总数】: 2,
"successful"【分片 - 成功】: 1,
"failed"【分片 - 失败】: 0
},
"_seq_no": 0,
"_primary_term": 1
}自定义唯一标识:POST 索引名/_doc/(自定义ID)
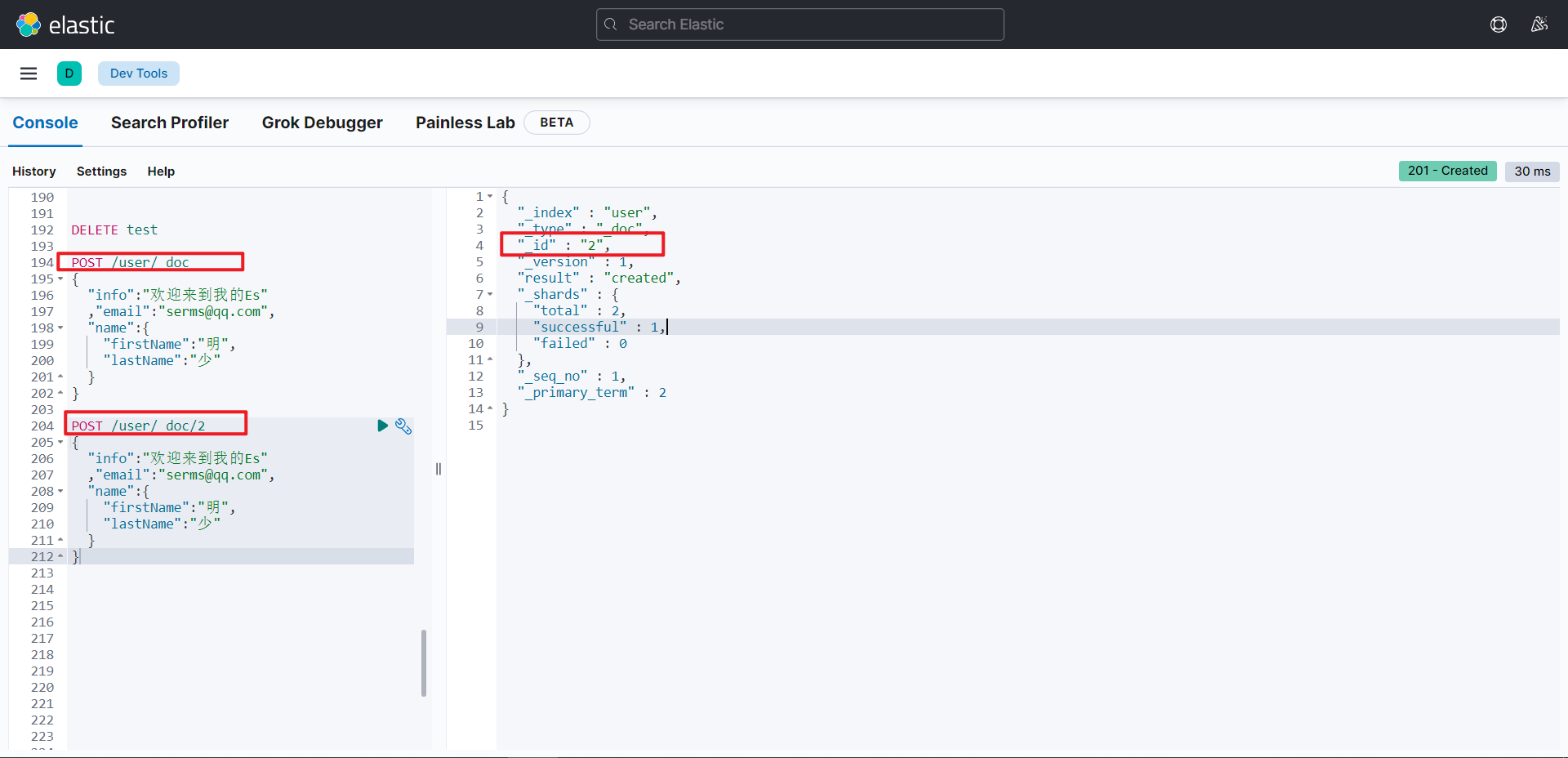
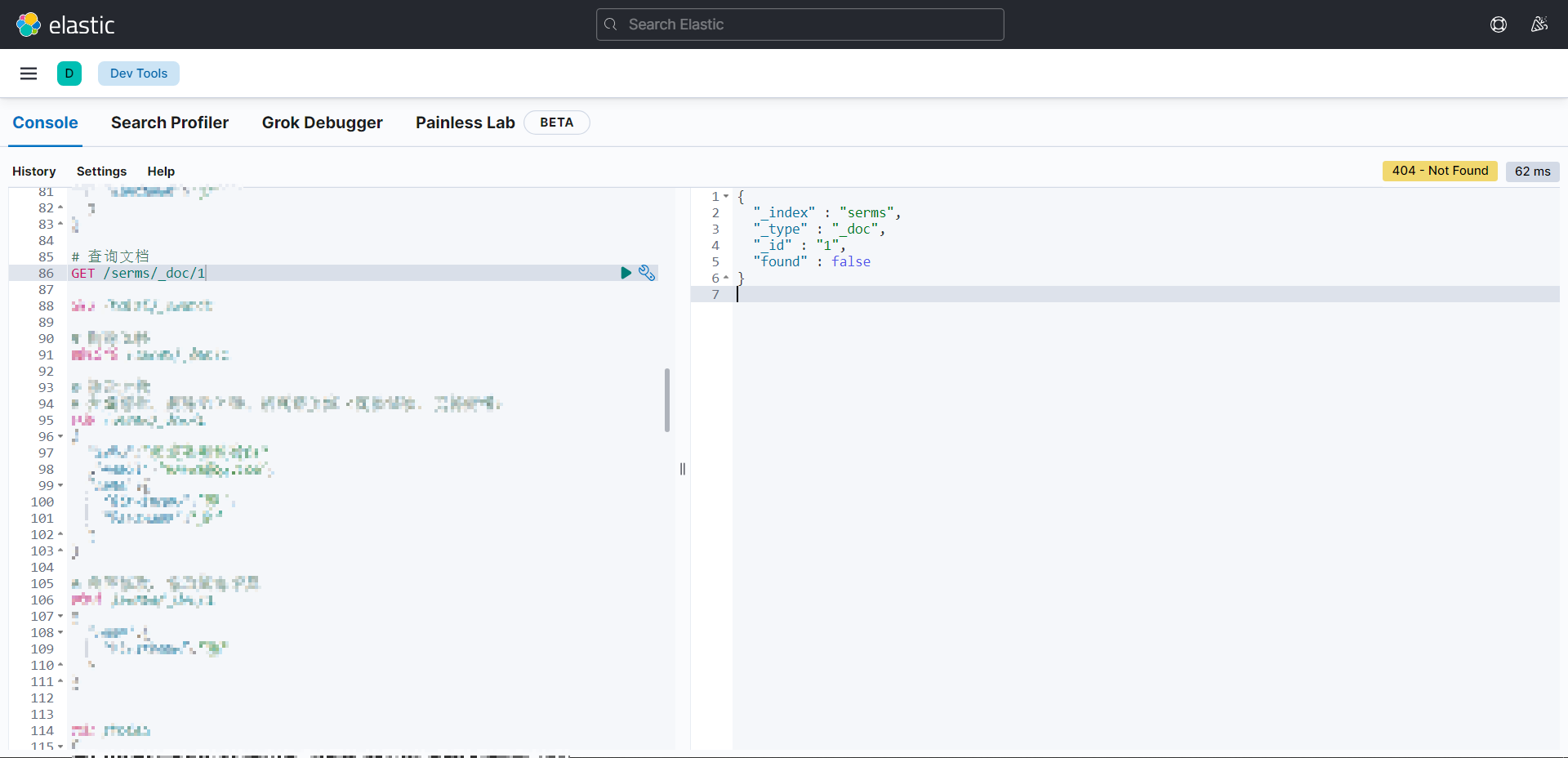
查看文档-GET
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
查看指定文档:GET 索引名/_doc/(唯一标识)
查看所有数据:GET 索引名/_search
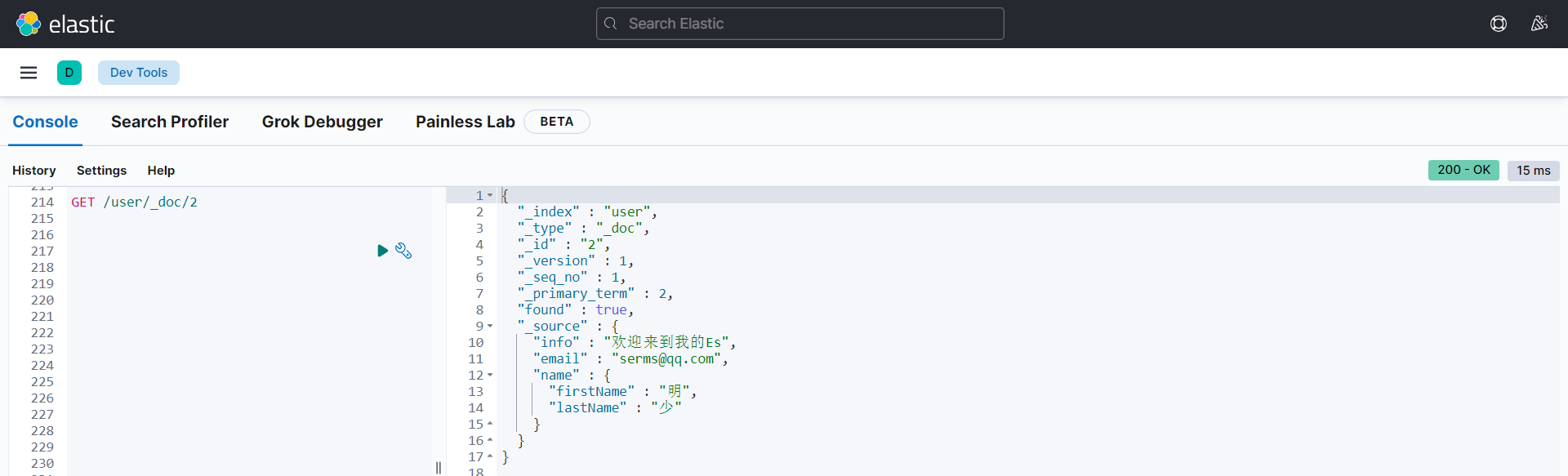
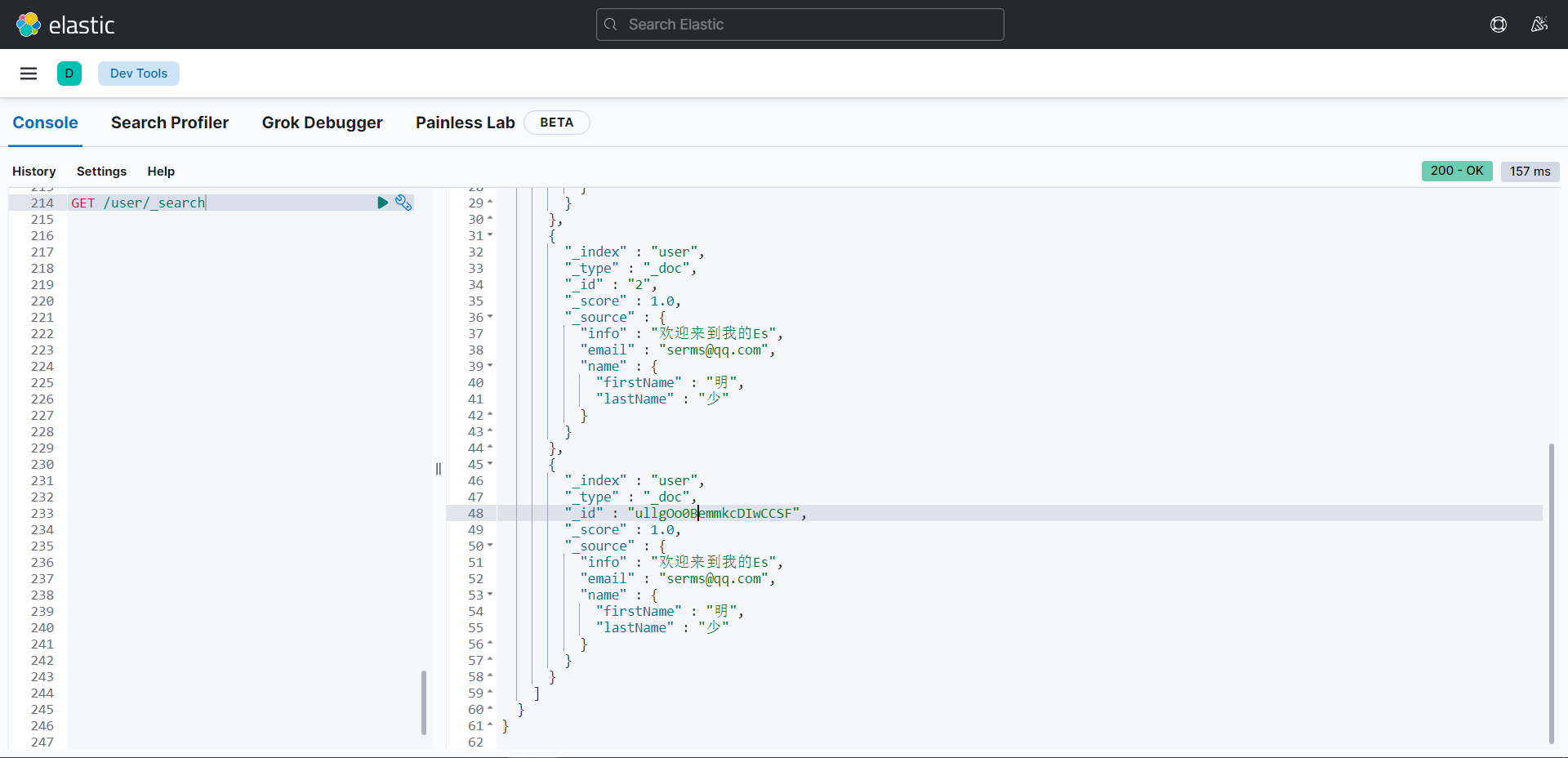
{
"_index"【索引】: "user",
"_id": "C1yqbIIBJVfoW_YKu2D5",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found"【查询结果】: true,
"_source"【文档源信息】: {
"userName": "A佳技术",
"age": "28"
}
}修改文档-POST
全局修改
POST 索引名/_doc/(唯一标识)
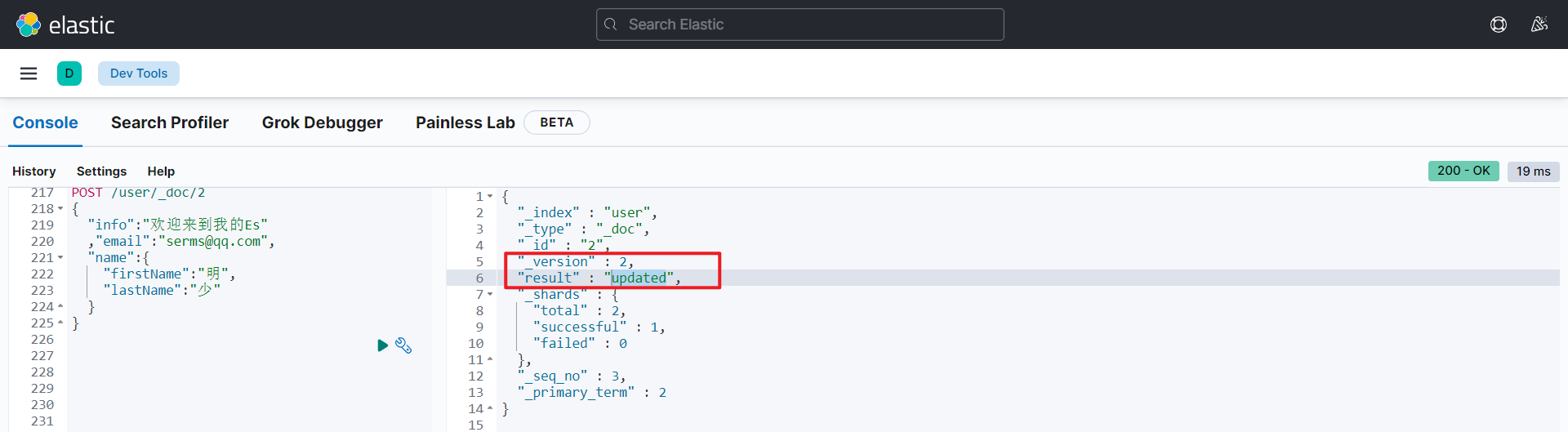
{
"_index": "user",
"_id": "C1yqbIIBJVfoW_YKu2D5",
"_version": 2,
"result"【更新操作】: "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}局部修改
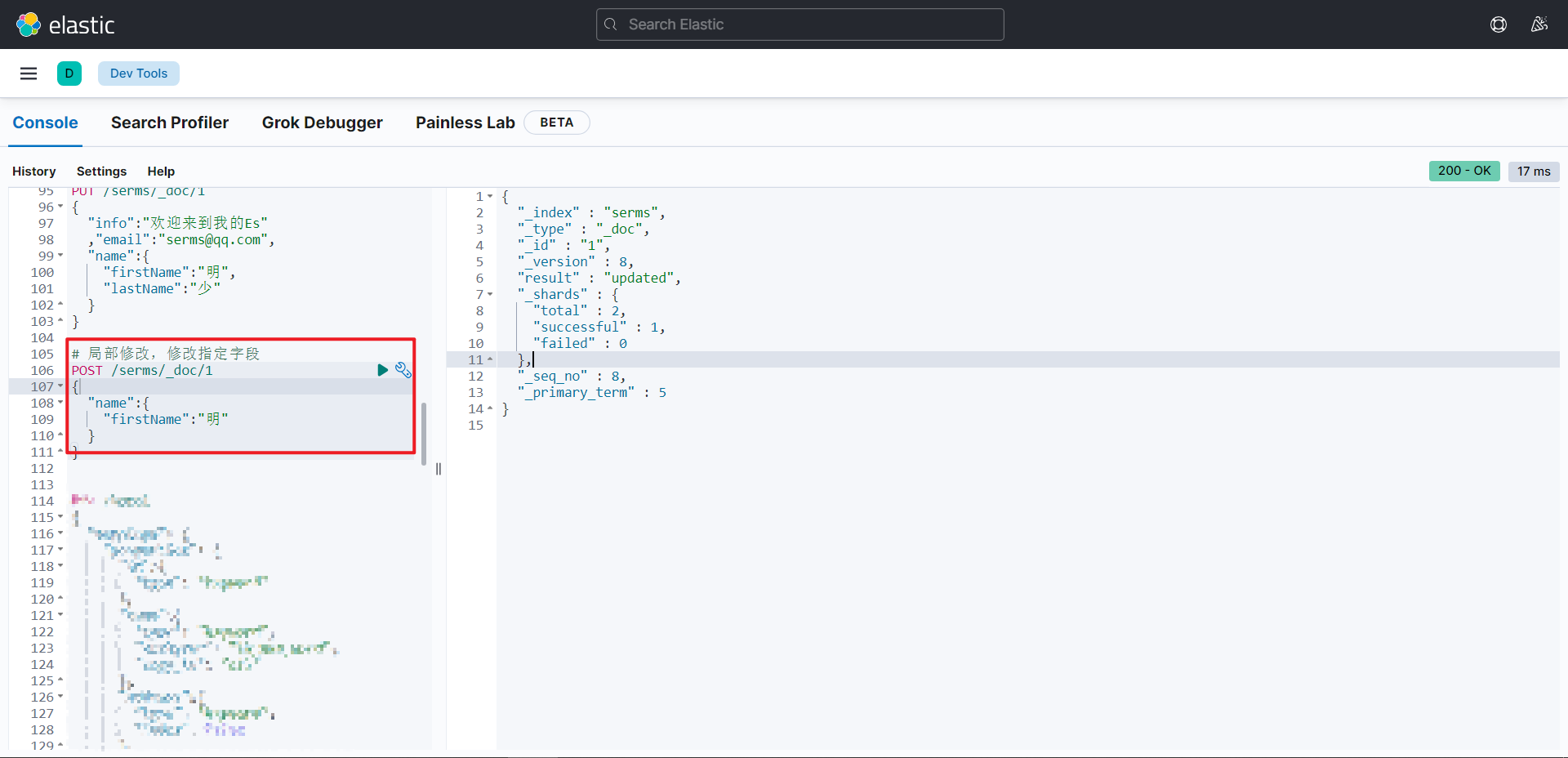
删除文档-DELETE
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)
DELETE 索引名/_doc/(唯一标识)
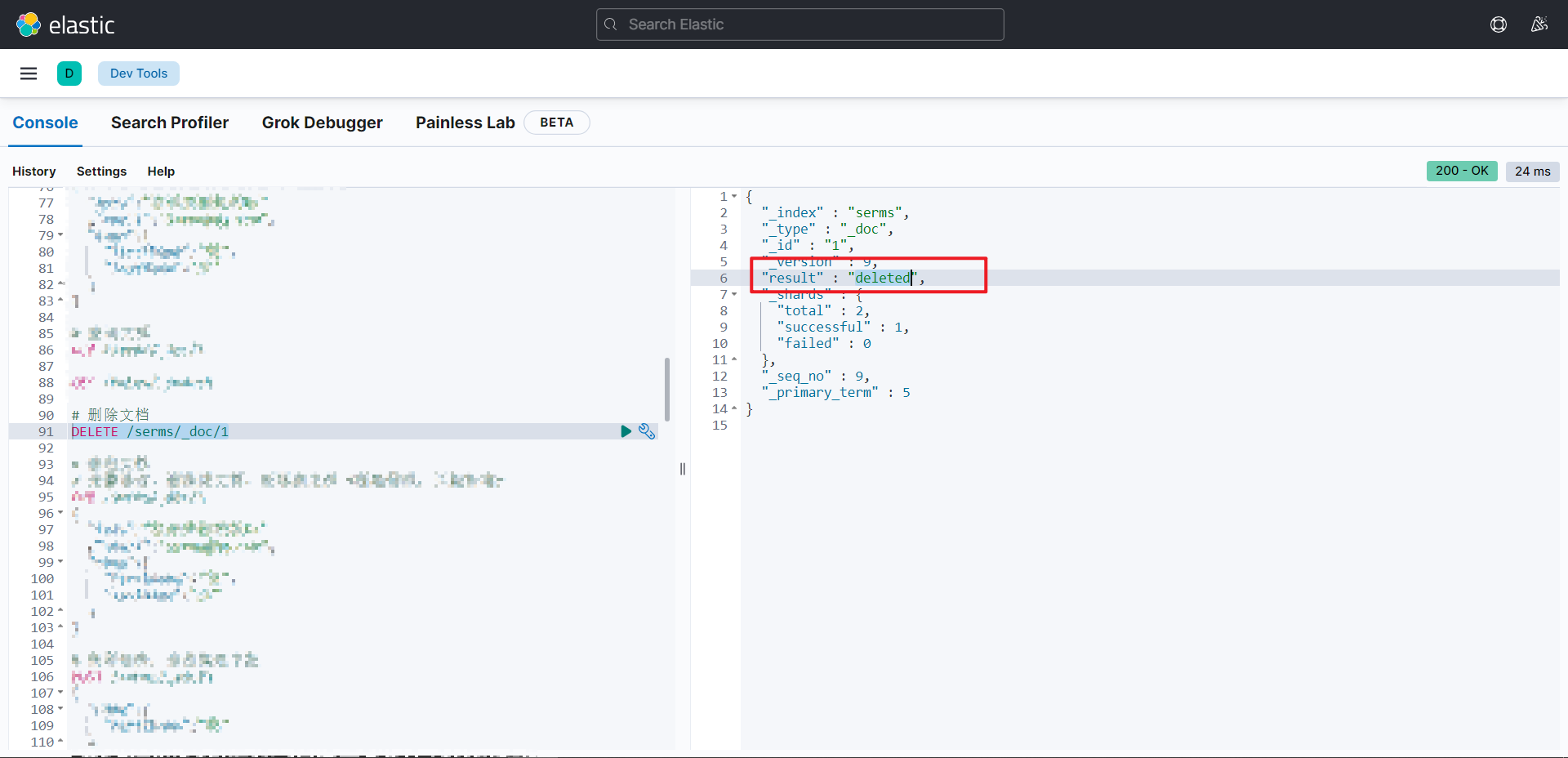
{
"_index": "user",
"_id": "C1yqbIIBJVfoW_YKu2D5",
"_version"【版本:对数据的操作,都会更新版本】: 5,
"result"【结果】: "deleted",# deleted 表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
条件删除文档-POST
首先分别增加多条数据,这里我添加了3条数据
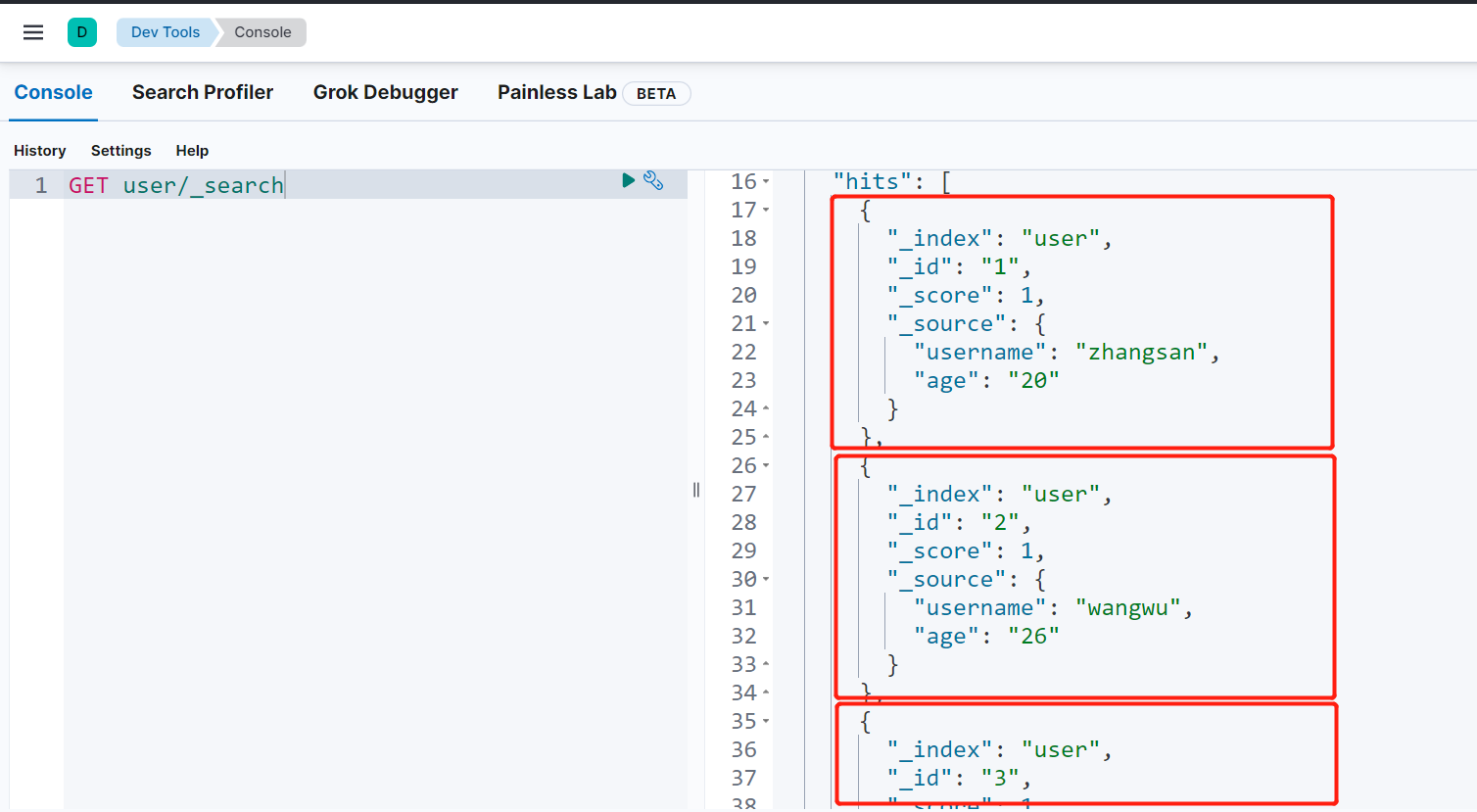
POST 索引名/_delete_by_query + 请求体条件
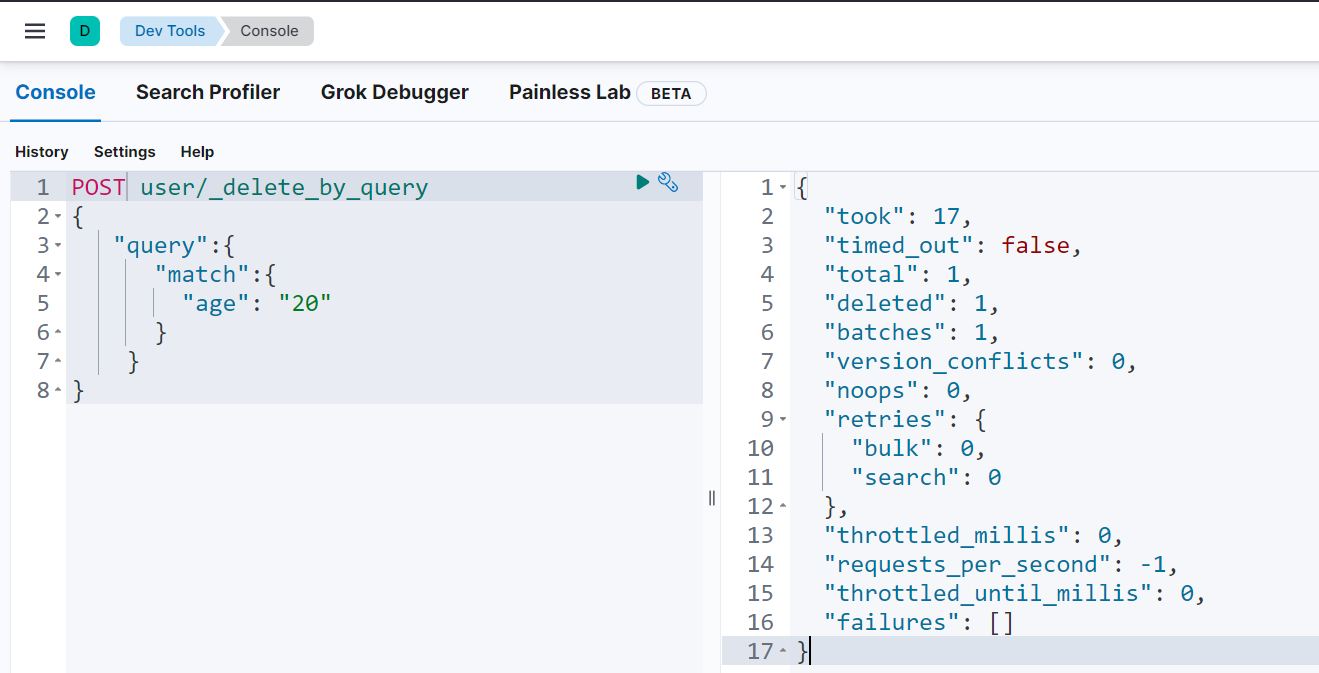
{
"took"【耗时】: 17,
"timed_out"【是否超时】: false,
"total"【总数】: 1,
"deleted"【删除数量】: 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}查看文档数据情况,年龄20已经删除
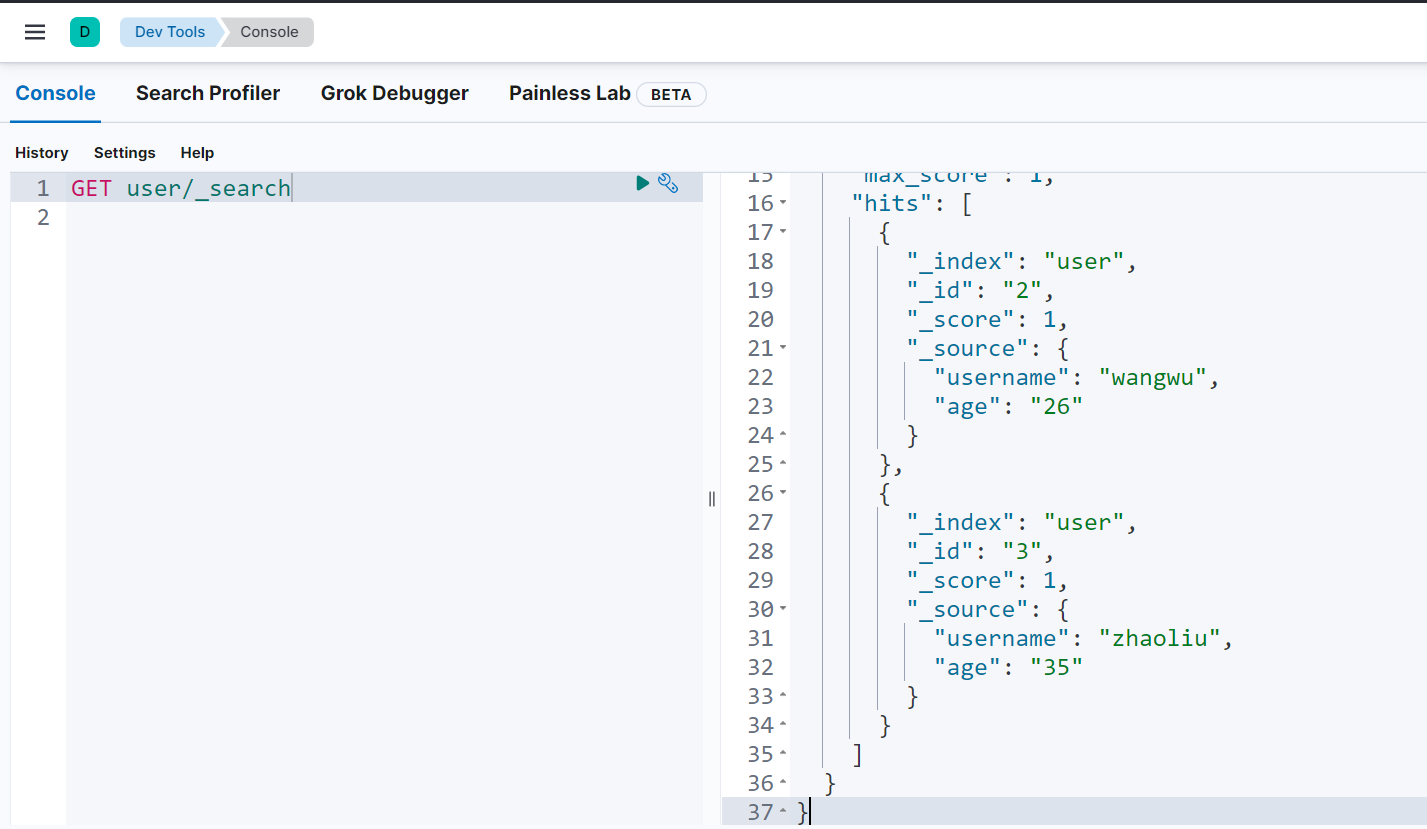
映射基本操作
原理
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
先创建索引-PUT
PUT hotel创建映射-PUT
为已经存在的索引库添加映射
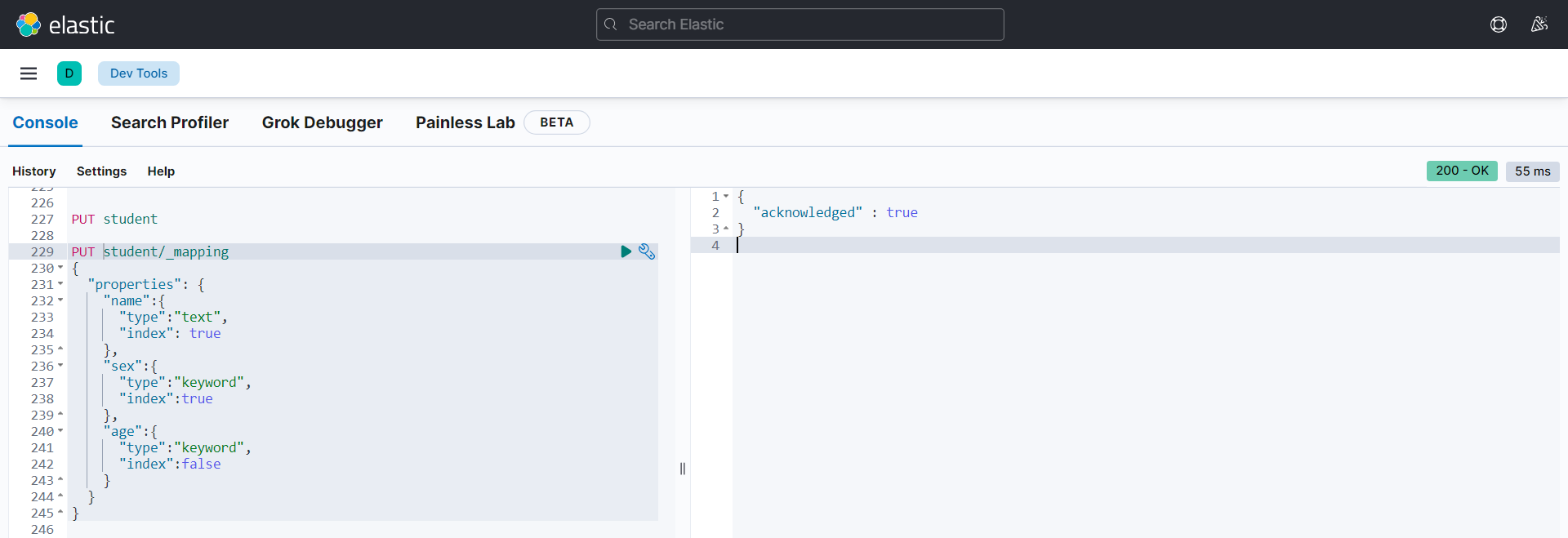
PUT 索引名/_mapping + 请求体内容
PUT student/_mapping
{
"properties": {
"name":{
"type":"text",
"index": true
},
"sex":{
"type":"keyword",
"index":true
},
"age":{
"type":"keyword",
"index":false
}
}
}
创建索引并添加映射
PUT /索引名称 {
“mappings”:{
"properties": {}
}
}
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "keyword",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "keyword",
"analyzer": "ik_max_word"
}
}
}
}映射数据说明:
字段名:任意填写
type:类型,Elasticsearch中支持的数据类型非常丰富,说几个关键的:String类型,又分两种text:可分词,支持模糊查询,支持准确查询,不支持聚合查询keyword:不可分词,数据会作为完整字段进行匹配,支持模糊查询,支持准确查询,支持聚合查询。
Numerical:数值类型,分两类基本数据类型:
long、integer、short、byte、double、float、half_float浮点数的高精度类型:
scaled_float
Date:日期类型Array:数组类型Object:对象
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为 false。
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置 "store": true 即可,获取独立存储的字段要比从 _source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
analyzer:分词器,这里的ik_max_word即使用ik 分词器
查看映射-GET
GET /索引/_mapping
添加字段
对于映射,只能进行字段添加,不能对字段进行修改或删除,如有需要,则重新创建映射。
PUT user/_mapping
{
"properties":{
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"address":{
"type":"text"
}
}
}
